Note
Click here to download the full example code
Short Square Analysis¶
Calculate features of Short Square sweeps
Out:
/home/docs/checkouts/readthedocs.org/user_builds/ipfx/envs/latest/lib/python3.6/site-packages/hdmf/spec/namespace.py:485: UserWarning: Ignoring cached namespace 'hdmf-common' version 1.1.0 because version 1.3.0 is already loaded.
% (ns['name'], ns['version'], self.__namespaces.get(ns['name'])['version']))
/home/docs/checkouts/readthedocs.org/user_builds/ipfx/envs/latest/lib/python3.6/site-packages/hdmf/spec/namespace.py:485: UserWarning: Ignoring cached namespace 'core' version 2.2.0 because version 2.2.5 is already loaded.
% (ns['name'], ns['version'], self.__namespaces.get(ns['name'])['version']))
import os
import matplotlib.pyplot as plt
from ipfx.dataset.create import create_ephys_data_set
from ipfx.feature_extractor import (
SpikeFeatureExtractor, SpikeTrainFeatureExtractor
)
from ipfx.stimulus_protocol_analysis import ShortSquareAnalysis
from ipfx.spike_features import estimate_adjusted_detection_parameters
from ipfx.epochs import get_stim_epoch
from ipfx.utilities import drop_failed_sweeps
# Download and access the experimental data from DANDI archive per instructions in the documentation
# Example below will use an nwb file provided with the package
nwb_file = os.path.join(
os.path.dirname(os.getcwd()),
"data",
"nwb2_H17.03.008.11.03.05.nwb"
)
# Create Ephys Data Set
data_set = create_ephys_data_set(nwb_file=nwb_file)
# Drop failed sweeps: sweeps with incomplete recording or failing QC criteria
drop_failed_sweeps(data_set)
short_square_table = data_set.filtered_sweep_table(
stimuli=data_set.ontology.short_square_names
)
short_square_sweeps = data_set.sweep_set(short_square_table.sweep_number)
# Select epoch corresponding to the actual recording from the sweeps
# and align sweeps so that the experiment would start at the same time
short_square_sweeps.select_epoch("recording")
short_square_sweeps.align_to_start_of_epoch("experiment")
# find the start and end time of the stimulus
# (treating the first sweep as representative)
stim_start_index, stim_end_index = get_stim_epoch(short_square_sweeps.i[0])
stim_start_time = short_square_sweeps.t[0][stim_start_index]
stim_end_time = short_square_sweeps.t[0][stim_end_index]
# Estimate the dv cutoff and threshold fraction
dv_cutoff, thresh_frac = estimate_adjusted_detection_parameters(
short_square_sweeps.v,
short_square_sweeps.t,
stim_start_time,
stim_start_time + 0.001
)
# Build the extractors
spfx = SpikeFeatureExtractor(
start=stim_start_time, dv_cutoff=dv_cutoff, thresh_frac=thresh_frac
)
sptfx= SpikeTrainFeatureExtractor(start=stim_start_time, end=None)
# Run the analysis
short_square_analysis = ShortSquareAnalysis(spfx, sptfx)
results = short_square_analysis.analyze(short_square_sweeps)
# Plot the sweeps at the lowest amplitude that evoked the most spikes
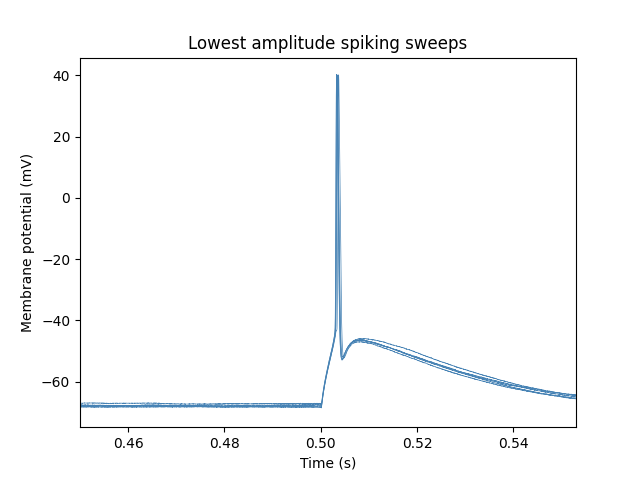
for i, swp in enumerate(short_square_sweeps.sweeps):
if i in results["common_amp_sweeps"].index:
plt.plot(swp.t, swp.v, linewidth=0.5, color="steelblue")
# Set the plot limits to highlight where spikes are and axis labels
plt.xlim(stim_start_time - 0.05, stim_end_time + 0.05)
plt.xlabel("Time (s)")
plt.ylabel("Membrane potential (mV)")
plt.title("Lowest amplitude spiking sweeps")
plt.show()
Total running time of the script: ( 0 minutes 9.096 seconds)